
Du tippst eine Frage in ChatGPT – und im Hintergrund zerlegt das Modell deinen Text sofort in winzige Bausteine: Tokens. Sie bestimmen, wie viel Text ChatGPT auf einmal verarbeiten kann, wie schnell es antwortet und – bei der Nutzung über die API – was es kostet.
Dieser Guide erklärt dir einfach und aktuell (Stand: Mai 2026), was Tokens sind, wie du sie zählst, welche Limits gelten und wie du Tokens – und damit Geld – sparst.
Kurz & knapp: Ein Token ist ein Textbaustein – meist ein kurzes Wort, ein Wortteil oder ein Satzzeichen. Als Faustregel gilt: 1 Token ≈ 4 Zeichen, oder 100 Tokens ≈ 75 englische Wörter. Deutsch braucht wegen langer, zusammengesetzter Wörter etwas mehr Tokens als Englisch. Die exakte Zahl für deinen Text ermittelst du mit einem Tokenizer.
Was sind Tokens bei ChatGPT?
Ein Token ist die kleinste Verarbeitungseinheit eines GPT-Modells. ChatGPT „liest“ Text nämlich nicht Wort für Wort wie wir Menschen, sondern zerlegt ihn zuerst in Tokens und rechnet dann nur noch mit diesen Bausteinen.
Ein Token kann sein:
- ein ganzes kurzes Wort – z. B. „Haus“
- ein Wortteil – „un“, „glaub“, „lich“ bei „unglaublich“
- ein einzelnes Zeichen, ein Leerzeichen oder ein Satzzeichen
Wichtig ist vor allem eins: Ein Token ist nicht dasselbe wie ein Wort und nicht dasselbe wie ein Zeichen. Häufige Wörter werden zu einem einzigen Token, seltene oder lange Wörter in mehrere zerlegt. ChatGPT „denkt“, rechnet und – über die API – bezahlt also in Tokens, nicht in Wörtern.
Eine kurze Abgrenzung, weil hier oft etwas durcheinandergerät: Der „Token“ in diesem Artikel ist eine Texteinheit. Gemeint ist damit nicht ein API-Zugangsschlüssel (Access Token) und auch kein Krypto-Token. Es geht ausschließlich darum, wie GPT-Modelle Text zählen.
Wie aus Text Tokens werden: die Tokenisierung
Das Zerlegen von Text in Tokens nennt man Tokenisierung. Dahinter steckt ein Verfahren namens Byte Pair Encoding (BPE): Häufig vorkommende Zeichenfolgen werden zu einem Token zusammengefasst, seltene Folgen in mehrere Teile aufgespalten.
Jedes Modell nutzt dafür ein festes „Vokabular“ an möglichen Tokens. Die aktuellen OpenAI-Modelle (GPT-4o, die o-Reihe sowie GPT-5) verwenden das Encoding o200k_base mit rund 200.000 möglichen Tokens – doppelt so viele wie die Vorgänger-Generation. Das größere Vokabular macht die Tokenisierung effizienter, besonders bei Sprachen, die nicht Englisch sind. Wer es ganz genau wissen will: OpenAI stellt den Tokenizer-Code offen als tiktoken auf GitHub bereit.
Für den Alltag reicht eine einfache Faustregel: Im Englischen entspricht ein Token im Schnitt etwa 4 Zeichen.
Wie viele Tokens hat mein Text?

Du musst Tokens nicht selbst ausrechnen – aber ein Gefühl dafür hilft, Kosten und Limits einzuschätzen. Diese Faustregeln decken die meisten Fälle ab:
| Einheit | Faustregel |
|---|---|
| 1 Token | ≈ 4 Zeichen (Englisch) |
| 100 Tokens | ≈ 75 englische Wörter |
| 1 Wort (Englisch) | ≈ 1,3 Tokens |
| 1 Wort (Deutsch) | ≈ 1,5–2 Tokens |
| 1 Satzzeichen | meist 1 Token |
| 1 Emoji oder Sonderzeichen | 1–3 Tokens |
Diese Werte sind Näherungen – der echte Wert hängt vom konkreten Text ab. Den exakten Token-Wert für deinen Text bekommst du mit einem Tokenizer: Text einfügen, Token-Zahl ablesen. In unseren OpenAI API Rechner haben wir genau so ein Werkzeug integriert – damit prüfst du in Sekunden, wie viele Tokens dein Prompt verbraucht.
Tokens in verschiedenen Sprachen: Deutsch vs. Englisch
Nicht jede Sprache ist gleich „token-effizient“. Der Grund: GPT-Modelle wurden überwiegend mit englischem Text trainiert – englische Wörter passen daher besonders oft in ein einziges Token.
- Englisch ist am effizientesten – kurze, häufige Wörter werden meist zu einem Token.
- Deutsch braucht mehr Tokens, vor allem wegen langer zusammengesetzter Wörter. Ein Ungetüm wie „Donaudampfschifffahrtsgesellschaft“ wird in viele Bausteine zerlegt.
- Französisch und Spanisch liegen dazwischen – Akzentzeichen wie „é“ oder „à“ kosten oft zusätzliche Tokens.
Ein Mini-Experiment mit unserem Tokenizer macht es greifbar. Wir haben drei nur fünf Zeichen kurze Schreibweisen des Wortes „hello“ geprüft:
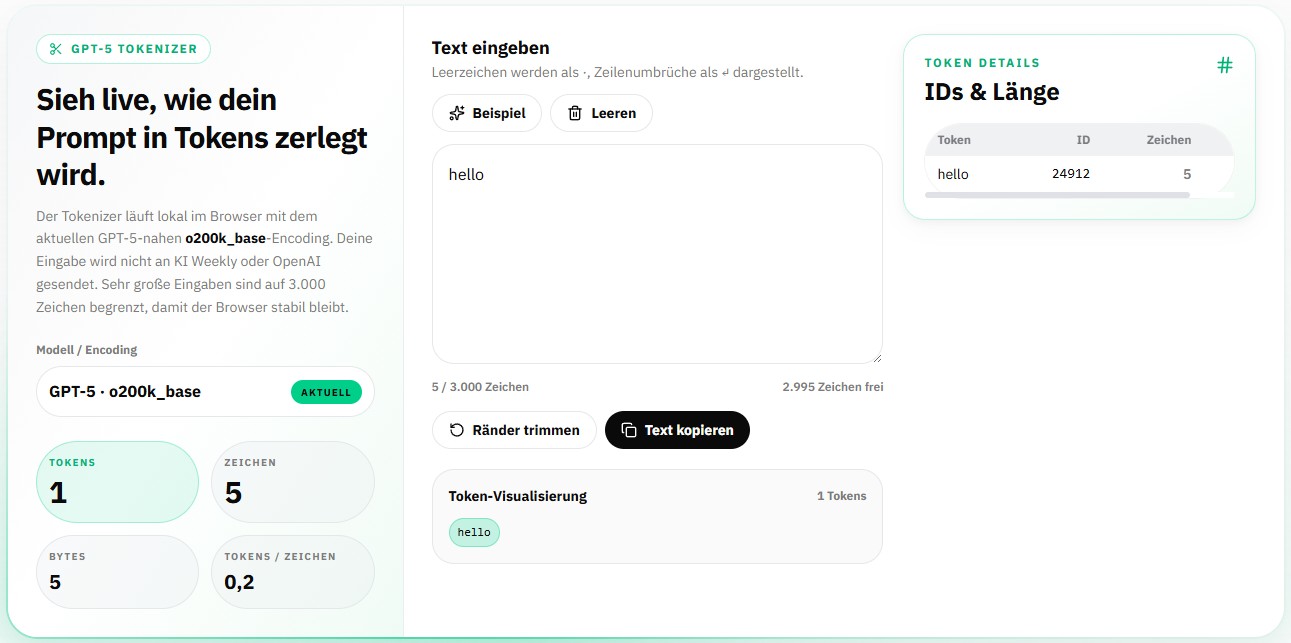
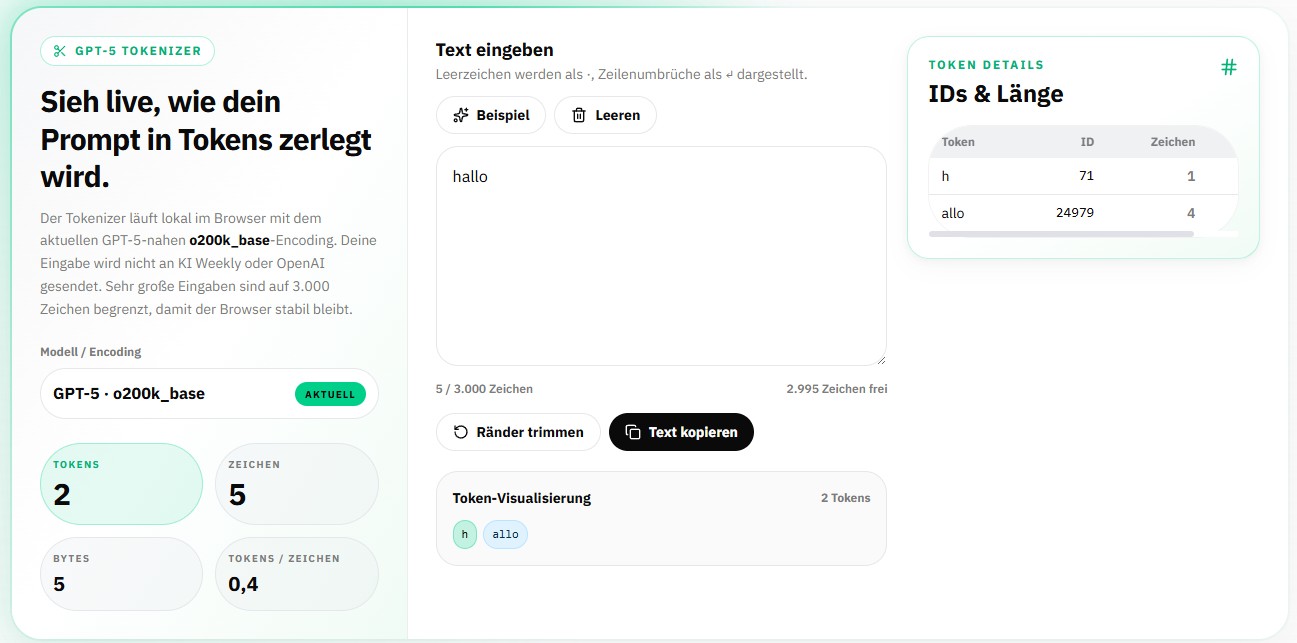
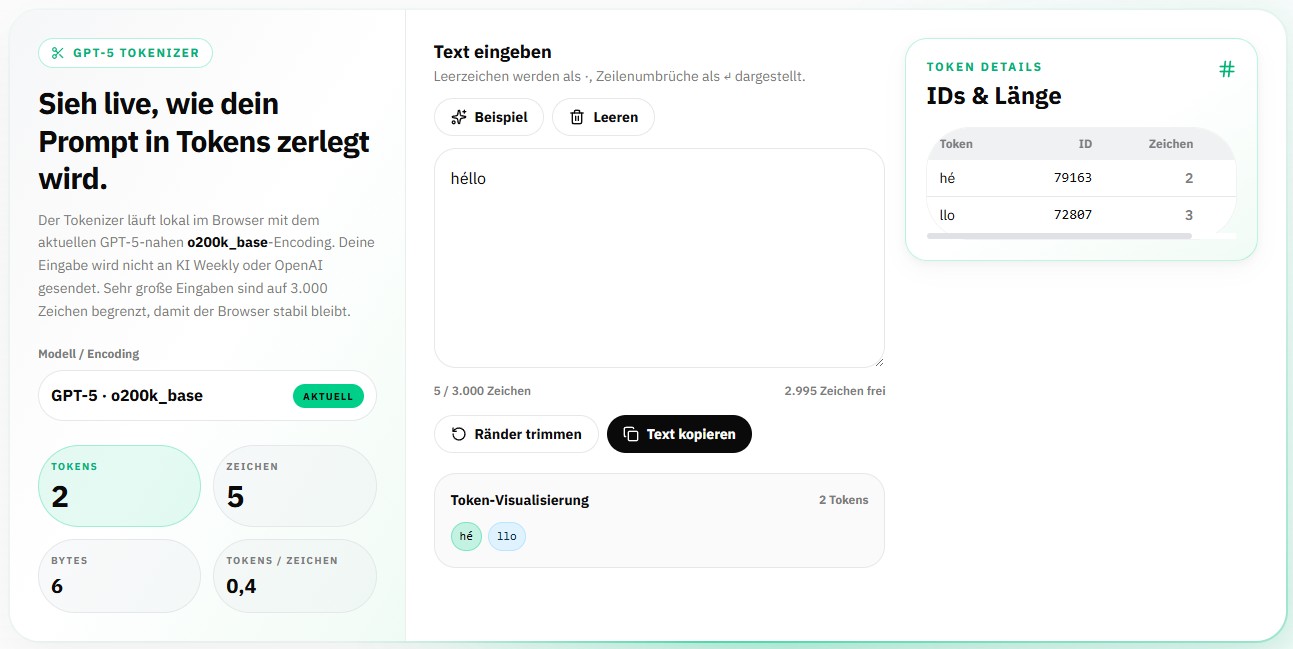
Gleiche Länge, völlig anderer Token-Verbrauch: Englisch kommt mit 1 Token aus, die deutsche Schreibweise und die Variante mit Akzent brauchen jeweils 2 Tokens. Über einen ganzen Text summiert sich dieser Unterschied spürbar.
Mit dem aktuellen o200k-Tokenizer ist der Abstand kleiner geworden als früher, aber Deutsch bleibt etwas „teurer“. Praktische Konsequenz: Wer die API auf Deutsch nutzt, sollte beim Kontextfenster und bei den Kosten etwas mehr Tokens einplanen. Probiere es einfach selbst aus – tippe deine eigenen Texte in unseren Tokenizer und vergleiche.
Was kostet ein Token?
Hier kommt es darauf an, wie du ChatGPT nutzt:
- In der ChatGPT-App (Free, Go, Plus, Pro) zahlst du einen festen Monatspreis. Tokens spielen hier nur als Limit eine Rolle, nicht als direkte Kosten.
- Über die OpenAI API zahlst du pro verbrauchtem Token – getrennt nach Input (dein Prompt) und Output (die Antwort des Modells). Output ist dabei deutlich teurer als Input.
So sehen die API-Preise der aktuellen Modelle aus (Stand: Mai 2026, pro 1 Million Tokens):
| Modell | Input | Output |
|---|---|---|
| GPT-5.5 | 5 $ | 30 $ |
| GPT-5.4 | 2,50 $ | 15 $ |
Die kleineren Varianten wie GPT-5.4 mini sind noch einmal deutlich günstiger. Zwei Spar-Hebel gibt es obendrauf: Wiederholt sich ein Teil deines Prompts, greift ein vergünstigter Preis für zwischengespeicherten Input (Caching); für nicht eilige Massen-Anfragen gibt die Batch API rund 50 % Rabatt.
Preise ändern sich häufig. Was dein konkreter Anwendungsfall kostet, rechnest du am schnellsten mit unserem OpenAI API Rechner aus – die offizielle Preisliste führt OpenAI unter openai.com/api/pricing.
Token-Limit & Kontextfenster: Wie viel Text passt rein?
Jedes Modell hat ein Kontextfenster – die maximale Zahl an Tokens, die Eingabe und Ausgabe zusammen umfassen dürfen. Man spricht auch vom „Token-Limit“.
Die aktuellen Spitzenmodelle GPT-5.5 und GPT-5.4 fassen bis zu 1 Million Tokens – genug für sehr lange Dokumente oder ganze Projekte. Kleinere Modelle wie GPT-5.4 mini liegen darunter. Welches Modell wie viel kann, vergleichen wir laufend in unserem KI-Modell-Ranking; die Modelle selbst erklären wir im großen GPT-Modelle-Guide.
Zwei Limits begegnen dir in der Praxis besonders oft:
- Abgeschnittene Antworten: Über die API begrenzt der Parameter
max_tokens(bzw.max_output_tokens) die Länge der Antwort. Ist der Wert zu niedrig, bricht die Antwort mitten im Satz ab. Die Lösung: den Wert erhöhen – oder das Modell von vornherein um eine kürzere Antwort bitten. In der ChatGPT-App genügt bei sehr langen Antworten oft ein einfaches „weiter“. - Nutzungslimits im Abo: Auch ChatGPT Free und Plus haben Grenzen, wie viele Nachrichten du in einem Zeitraum mit den Top-Modellen senden kannst. Welche Stufe wie viel erlaubt, zeigt unser ChatGPT Abo-Vergleich.
Tokens sparen: 6 praktische Tipps

Weniger Tokens bedeuten niedrigere API-Kosten, schnellere Antworten und mehr Platz im Kontextfenster. So holst du das raus:
- Präzise formulieren. Knappe, eindeutige Prompts brauchen weniger Tokens und liefern bessere Ergebnisse. Unser kostenloser Prompt-Generator hilft dir dabei.
- Nur nötigen Kontext mitgeben. Füge nicht das ganze Dokument ein, wenn ein Absatz reicht.
- Lange Texte vorab zusammenfassen und nur die Zusammenfassung weiterverwenden.
- Das passende Modell wählen. Für einfache Aufgaben reicht oft ein kleineres, günstigeres Modell.
- Den Output begrenzen – z. B. mit
max_tokensoder der Anweisung „antworte in maximal drei Sätzen“. - Wiederkehrende Prompt-Bausteine über das Prompt-Caching der API nutzen.
Fazit
Tokens sind die Währung, in der GPT-Modelle rechnen. Das Wichtigste in Kürze:
- Ein Token ist ein Textbaustein – als Faustregel rund 4 Zeichen bzw. 100 Tokens ≈ 75 englische Wörter.
- Deutsch verbraucht mehr Tokens als Englisch – lange Komposita und Sonderzeichen kosten extra.
- Das Token-Limit ist das Kontextfenster: So viel Text passt insgesamt rein.
- In der API zahlst du pro Token, in der ChatGPT-App pauschal.
- Für exakte Zahlen nutzt du einen Tokenizer – am schnellsten direkt in unserem OpenAI API Rechner.
Du willst bei neuen Modellen, Preisen und KI-Tools auf dem Laufenden bleiben? Aktuelle Entwicklungen findest du in unseren KI-Schlagzeilen, die kompakte Wochenübersicht im KI Weekly Newsletter – jede Ausgabe gibt es im Archiv. Mehr Tiefe und werbefreie Inhalte bekommst du mit KI Weekly Plus, weitere Erklärstücke sammeln wir im Blog.
Häufige Fragen zu ChatGPT-Tokens (FAQ)
Deine Frage ist nicht dabei? Stell sie unseren Expertinnen und Experten über Deine Frage.
Was ist ein Token bei ChatGPT?
Ein Token ist die kleinste Texteinheit, mit der ein GPT-Modell arbeitet – meist ein kurzes Wort, ein Wortteil oder ein Satzzeichen. ChatGPT zerlegt jeden Text zunächst in Tokens und verarbeitet dann nur noch diese Bausteine.
Wie viele Tokens sind 1.000 Wörter?
Als grobe Faustregel entsprechen 1.000 englische Wörter rund 1.300 Tokens. Im Deutschen sind es eher 1.500 bis 2.000 Tokens, weil Wörter häufiger in mehrere Tokens zerlegt werden. Den genauen Wert liefert ein Tokenizer.
Wie zähle ich Tokens in meinem Text?
Am einfachsten mit einem Tokenizer-Tool: Text einfügen, Token-Zahl ablesen. In unseren OpenAI API Rechner ist ein solcher Tokenizer integriert. So siehst du sofort, wie viele Tokens dein Prompt verbraucht.
Was ist das Token-Limit von ChatGPT?
Das Token-Limit ist das Kontextfenster eines Modells – die maximale Zahl an Tokens für Eingabe und Ausgabe zusammen. Aktuelle Spitzenmodelle wie GPT-5.5 fassen bis zu 1 Million Tokens. Zusätzlich gibt es je nach Abo Nutzungslimits, wie oft du die Top-Modelle einsetzen darfst.
Kosten Tokens in ChatGPT Geld?
In der ChatGPT-App zahlst du einen festen Monatspreis – einzelne Tokens kosten dort nichts extra. Geld pro Token fällt nur bei der Nutzung über die OpenAI API an, getrennt nach Input und Output.
Wie bekomme ich einen ChatGPT-Token?
Hier werden zwei Dinge oft verwechselt. Tokens als Texteinheiten musst du dir nicht „besorgen“ – sie werden automatisch gezählt. Suchst du dagegen einen *API-Zugangsschlüssel* (oft ebenfalls „Token“ genannt), erstellst du diesen im OpenAI-Entwicklerbereich unter „API keys“.
Warum braucht Deutsch mehr Tokens als Englisch?
GPT-Modelle wurden überwiegend mit englischem Text trainiert. Englische Wörter passen daher häufiger in ein einzelnes Token, während deutsche Wörter – besonders lange Komposita – in mehrere Tokens zerlegt werden.
Warum wird meine ChatGPT-Antwort abgeschnitten?
Meist ist das Antwort-Limit erreicht. Über die API begrenzt der Parameter max_tokens die Antwortlänge – ist er zu niedrig, bricht der Text ab. Erhöhe den Wert oder fordere eine kürzere Antwort an. In der ChatGPT-App hilft oft ein einfaches „weiter“.
Weiterlesen
Weitere Blogbeiträge

ChatGPT-Modelle 2026: Alle GPT-Versionen im Überblick

Der gpt 4 turbo Business Guide für 2026
Claude Code: Modell oder Effort Level – was macht KI wirklich besser?




